Daten aus PDF-Dokumenten extrahieren und strukturieren
Was du nach diesem Kapitel kannst: Du kannst einen Workflow aufbauen, der Dokumenteninhalte ausliest und gezielt strukturierte Daten daraus extrahiert. Du verstehst, wie Read File Agent und Generative AI Agent zusammenspielen — und du weißt, wie du einen Extraktions-Prompt formulierst, der zuverlässig saubere, maschinenlesbare Ergebnisse liefert.
Sample-Workflow herunterladen
1. Das Grundprinzip
PDF-Dokumente (z. B. Rechnungen, Bestell-PDFs, 2D-Zeichnungen in PDF-Dateien) werden in der integrierten Dateiverwaltung von 42°flow abgelegt, wenn sie per Mail, Web Formular oder ähnlichem einem Workflow zugeführt wurden. Agents können im Workflow über den Dateipfad auf die Dateien zugreifen. Der Dateipfad wird erstmalig von dem Agent ausgegeben, der die Datei in die Plattform holt. Um ihren Inhalt auswerten zu können, müssen zwei Dinge passieren:
- Lesen: Der Dateiinhalt wird als Text extrahiert und in die Nachricht geschrieben.
- Verstehen: Ein KI-Modell analysiert den Text und gibt die relevanten Informationen strukturiert zurück.
- Bereinigen und Strukturieren: Sicherstellen, dass die KI-Ausgabe den Vorgaben entspricht, ggf. bereinigen und für die Weiterverarbeitung strukturieren.
Die ersten beiden Schritte werden von zwei verschiedenen Agenten übernommen: dem Read File Agent und dem Generative AI Agent. Da der Generative AI Agent einen serialisierten String ausgibt, für die gezielte Weiterverarbeitung aber eine JSON-Struktur benötigt wird, muss die JSON geparst werden (JSON Parse Agent). Damit dies zuverlässig funktioniert ist vorab der KI-Output zu überprüfen und zu bereinigen (Message Formatting Agent).
2. Schritt 1 — Dateiinhalt auslesen mit dem Read File Agent
Der Read File Agent liest eine Datei und macht ihren Inhalt im Workflow verfügbar. In der Konfiguration werden zwei Dinge angegeben:
- Input-Key: Der Schlüssel in der eingehenden Nachricht, der den Pfad zur Datei enthält.
- Output-Key: Der Schlüssel, unter dem der extrahierte Dateiinhalt in der Nachricht gespeichert werden soll.
Der extrahierte Inhalt wird als serialisierter String ausgegeben — also als reiner Text. Dieser Text ist jedoch bereits vorstrukturiert: Tabellen werden beispielsweise mit HTML-Tabellen-Tags (<table>, <tr>, <td>) abgebildet. Das macht den Output direkt geeignet für die KI-basierte Weiterverarbeitung, da das Modell die Tabellenstruktur erkennen und korrekt interpretieren kann.
[Eingehende Nachricht]
→ Schlüssel "file_path": "/share/dokumente/rechnung_2026_042.pdf"
[Read File Agent]
→ liest Datei von "file_path"
→ schreibt Inhalt als String unter Schlüssel "file_content"
[Ausgehende Nachricht]
→ Schlüssel "file_path": "/share/dokumente/rechnung_2026_042.pdf"
→ Schlüssel "file_content": "<table><tr><td>Pos.</td><td>Artikel</td>..."
3. Schritt 2 — Daten extrahieren mit dem Generative AI Agent
Der Generative AI Agent erhält den extrahierten Dateiinhalt und analysiert ihn anhand eines definierten Prompts. Seine Aufgabe: relevante Informationen identifizieren, interpretieren und als strukturiertes JSON zurückgeben.
Die Qualität der Extraktion hängt fast vollständig von der Qualität des Prompts ab. Die folgenden Abschnitte beschreiben, was einen zuverlässigen Extraktions-Prompt ausmacht.
WICHTIG:
- Vollständig korrekte Ausgabe ist mit möglichst vielen Beispiel-Dokumenten zu testen. Zu Beginn mit sehr einfachen Dokumenten, aber wichtig sind vor allem die schwierigen Dokumente. Schwierige Dokumente sind beispielsweise an folgenden Indikatoren zu erkennen:
- Viele ähnlich klingende Inhalte (Verwechslungsgefahr)
- Nicht beschriftete Inhalte, z. B. eine Bestellnummer, die im Dokument nicht als Bestellnummer gekennzeichnet ist
- Es kommt trotz sorgfältig gewähltem Prompt hin und wieder dazu, dass Inhalte nicht korrekt ausgegeben, aufbereitet oder sogar ganz vergessen werden. Baue hierzu anschließende Vollständigkeitsprüfungen ein und wiederhole die Datenextraktion durch weitere nachfolgende Generative AI Agents für die spezifischen fehlenden Inhalte oder korrigiere Formate z. B. durch einen JavaScript Agent
3.1. Einen Extraktions-Prompt richtig aufbauen
Ausgabe strikt auf reines JSON beschränken
Das ist die wichtigste Einzelanweisung im gesamten Prompt: Das Modell darf ausschließlich das JSON-Objekt ausgeben — keine einleitenden Sätze, keine Erklärungen, kein Markdown wie ```json. Jede zusätzliche Ausgabe führt dazu, dass das Ergebnis nicht maschinell weiterverarbeitet werden kann.
Gib ausschließlich das JSON-Objekt zurück – ohne Einleitung, Kommentare,
Erklärungen oder Markdown-Formatierung.
Das Zielschema vollständig definieren
Das Modell braucht ein exaktes Zielschema — eine Vorlage des JSON-Objekts, das es befüllen soll. Jedes Feld sollte kommentiert oder beschrieben sein, damit das Modell weiß, was erwartet wird. Felder, die nicht erkannt werden, sollen explizit als null ausgegeben werden — niemals erfunden oder geraten.
Beispiel für eine Zielstruktur:
{
"dokument_typ": "Rechnung | Lieferschein | Auftragsbestaetigung",
"dokument_id": "Eindeutige Kennung des Dokuments oder null",
"lieferant_name": "Vollständiger Name des Lieferanten",
"dokument_datum": "YYYY-MM-DD oder null",
"positionen": [
{
"artikelnummer": "Artikel- oder Positionsnummer",
"beschreibung": "Mehrzeilige Beschreibung mit \\n",
"menge": "Anzahl mit Einheit, z. B. '5 ST'",
"position_typ": "Produkt | Logistik-Zusatz"
}
]
}
Felder präzise definieren — mit Regeln und Fallbacks
Vage Feldbeschreibungen führen zu vagen Ergebnissen. Jedes Feld, das eine Besonderheit hat, braucht eine explizite Regel. Exemplarische Präzisierungen:
- Erkennungsmuster: Wie erkennt das Modell dieses Feld im Dokument? Welche Bezeichnungen kommen vor ("Rechnungsdatum", "Datum", "Ausgestellt am")?
- Datumsformate: Immer normieren — im Dokument steht
06.03.2026, im JSON soll2026-03-06stehen. - Vererbungsregeln: Wenn ein Wert im Dokumentkopf steht und sich auf alle Positionen bezieht (z. B. eine Bestellnummer), muss das Modell diesen Wert auf jede Position übertragen.
- Fallbacks und Nullwerte: Wenn ein Wert nicht erkennbar oder nicht vorhanden ist — explizit
null, nie eine Erfindung. - Kategorisierungen innerhalb von Positionen: Zum Beispiel unterscheiden, ob eine Position ein Produkt oder eine Logistikleistung (Palette, Versand) ist.
Regex-Muster als Erkennungshilfe
Für Felder mit klarem Format — etwa Bestellnummern, Artikelnummern oder strukturierte Kennzeichen — lohnt es sich, dem Modell Regex-Muster als Orientierung mitzugeben. Das verhindert, dass das Modell ähnlich aussehende Werte (Telefonnummern, Lieferscheinnummern) verwechselt.
Erkenne Bestellnummern ausschließlich im Format AB\d{5} (z. B. AB12345).
Verwende keine anderen Nummern als Ersatz — fehlt die Nummer, setze null.
Eine interne Konsistenz-Checkliste einbauen
Für komplexe Extraktionen ist es sinnvoll, am Ende des Prompts eine stille Checkliste einzubauen — Prüfschritte, die das Modell intern durchläuft, bevor es das JSON ausgibt. Diese Checkliste erscheint nicht in der Ausgabe, beeinflusst aber die Qualität des Ergebnisses:
Prüfe still vor der Ausgabe:
- Enthält das JSON nur reines JSON, kein Markdown?
- Sind alle Datumsangaben im Format YYYY-MM-DD?
- Sind alle Positionen vollständig mit Mengenangaben?
- Wurden fehlende Werte als null gesetzt, nicht erfunden?
Dateiinhalt per Liquid Template einfügen
Der extrahierte Dateiinhalt aus dem Read File Agent wird per Liquid Template in den Prompt eingesetzt:
Hier ist der Textauszug:
{{ file_content }}
Der Schlüssel file_content muss dabei dem Output-Key entsprechen, der im Read File Agent konfiguriert wurde.
4. Ergebnis weiterverarbeiten
Der Generative AI Agent gibt sein Ergebnis als String zurück — auch wenn dieser String ein JSON-Objekt enthält. Bevor die extrahierten Daten in nachgelagerten Schritten genutzt werden können (z. B. in eine Datenbank geschrieben oder an eine API übergeben), muss dieser String in der Regel geparst werden.
⚠️ Trotz strikter Ausgabeanweisung kann das Modell gelegentlich Markdown-Fences ausgeben (
```json ... ```). Es empfiehlt sich, nach dem Generative AI Agent einen kurzen Bereinigungsschritt einzuplanen — zum Beispiel per Message Formatting Agent — der diese Umrahmung entfernt, bevor der String druch einen JSON Parse Agent geparst wird.
Hier eine exemplarische Message Formatting Agent Konfiguration zur Bereinigung den KI-Outputs.
{
"produces_unsafe_messages": false,
"accept_unsafe_messages": "reject",
"instructions": {
"clean_json": "{{clean_json}}"
},
"matchers": [
{
"path": "{{generation}}",
"regexp": "json\\n(?<clean_json>{[\\s\\S]*?})\\n"
},
{
"path": "{{generation}}",
"regexp": "\\n(?<clean_json>{[\\s\\S]*?})\\n"
},
{
"path": "{{generation}}",
"regexp": "(?<clean_json>{[\\s\\S]*})"
}
],
"mode": "merge"
}
🔗 Für die zuverlässige Weiterverarbeitung in nachgelagerten Schritten empfiehlt sich das Muster der SQL-Persistenz: Kapitel [[Zustandsnormalisierung durch SQL-Persistenz]]
5. Typische Anwendungsfälle
Rechnungsverarbeitung Eingehende Lieferantenrechnungen werden automatisch ausgelesen: Rechnungsnummer, Datum, Lieferant, Positionen mit Artikelnummern, Mengen und Bestellreferenzen werden strukturiert extrahiert und zur Buchung oder Prüfung an nachgelagerte Systeme übergeben.
Auftragsverarbeitung Auftragsbestätigungen von Lieferanten werden ausgelesen und mit den internen Bestelldaten abgeglichen — automatisch, ohne manuelle Dateneingabe.
Lieferscheinverarbeitung Lieferscheine werden bei Wareneingang verarbeitet: gelieferte Positionen und Mengen werden extrahiert und gegen offene Bestellungen geprüft.
In all diesen Szenarien ist das Extraktionsmuster dasselbe — es ändert sich nur das Zielschema und der Prompt-Kontext.
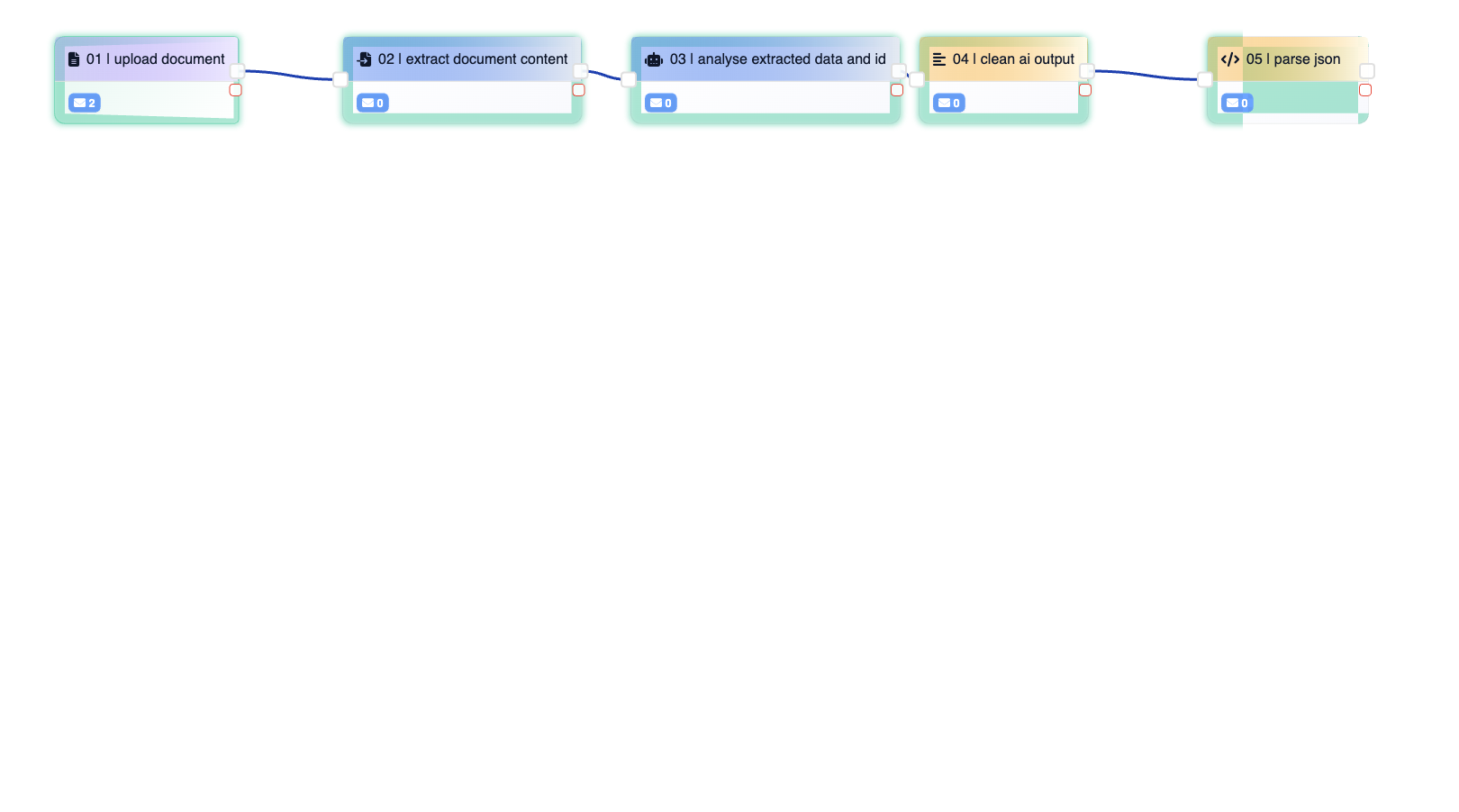
6. Zusammenfassung: Der vollständige Extraktions-Workflow
[Read File Agent]
→ liest Datei, schreibt Inhalt als String unter Output-Key
↓
[Generative AI Agent]
→ Prompt: Zielschema + Feldregeln + Regex-Hinweise + Konsistenz-Checkliste
→ Ausgabe: reines JSON als String
↓
[Message Formatting Agent]
→ bereinigt KI-Output
↓
[JSON Parse Agent]
→ parst JSON
↓
[Weiterverarbeitung]
→ z. B. Datenbank, ERP, API, Prüflogik
7. Checkliste: Was ein guter Extraktions-Prompt enthält
| Element | Warum wichtig |
|---|---|
| Strikte JSON-only-Anweisung | Verhindert unverarbeitbare Freitext-Ausgaben |
| Vollständiges Zielschema mit Beispiel | Modell weiß genau, was erwartet wird |
| Präzise Felddefinitionen mit Erkennungsmerkmalen | Verhindert Fehlzuordnungen |
| Explizite Nullwert-Regel | Keine erfundenen Werte |
| Datumsformat-Normierung | Konsistente, maschinenlesbare Ausgabe |
| Regex-Muster für strukturierte Felder | Verhindert Verwechslungen mit ähnlichen Werten |
| Vererbungsregeln für wiederkehrende Werte | Korrekte Zuordnung auf Positionsebene |
| Interne Konsistenz-Checkliste | Qualitätskontrolle vor der Ausgabe |
📹 Video zu diesem Kapitel: [Platzhalter — Screencast: Read File Agent konfigurieren + Extraktions-Prompt aufbauen + Ergebnis prüfen] 📸 Screenshots: [Platzhalter — Read File Agent Konfiguration, Generative AI Agent Prompt, Beispiel-JSON-Ausgabe]
Vorheriges Kapitel: [[Dokumente kategorisieren]] Nächstes Kapitel: [[Zustandsnormalisierung durch SQL-Persistenz]]